![[Compilers] Ch1 导论: Introduction](/images/24-09/24-09-23-01.png)
CH1 Introduction
编译原理一书, Introduction一章的阅读笔记. 因为是introduction所以不用看得那么认真, 随便看看就好. 需要把热情留到后面.
在写这篇博客时, 对编译原理的整体理解还不是很深入, 因此可能有错漏. 预计会在全部学完之后, 对这篇introduction中的内容进行检查更正.
Language Processors
编译器(complier)是一类Language Processors, 它接受源程序(source program)作为输入, 并将目标程序作为输出(target program). 之后, target program会完成将input转换为output的任务.
而解释器(interpreter)是另一类Language Processors. 它同时接受source program和input作为输入, 并得到output作为输出.
两者对比:
- 编译器生成的目标程序, 往往经过更好的优化, 在运行速度上具有优势
- 解释器则具有更强的灵活性, 不需要在每次运行前进行编译工作, 能够更快速地进行测试和debug
有的高级语言使用编译器, 有的则使用解释器, 而有的语言则使用两者的结合, 如JAVA.
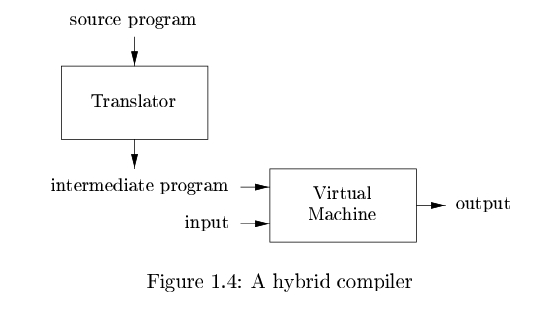
The Structure of a Complier
- 大致介绍了Complier的内部结构.
- 可将Complier的工作大致分为analysis与synthesis两部分
- analysis过程, 对原语言进行分析, 得到各种结构化的符号与信息, 如符号表(Symbol Table); synthesis过程利用这些信息, 构建出目标语言, 如机器代码.
- 更具体地, 可按照Complier的工作流对其进行拆分, 大致结构如下图:
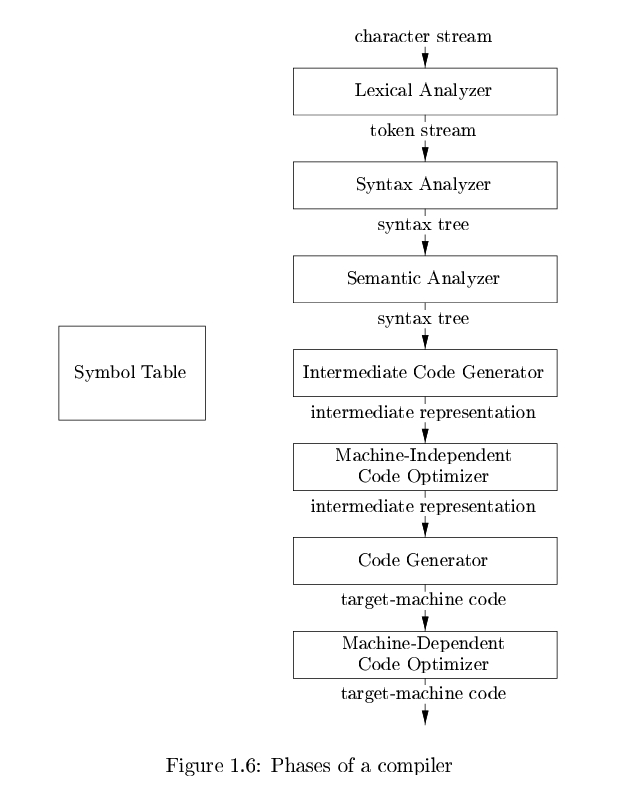
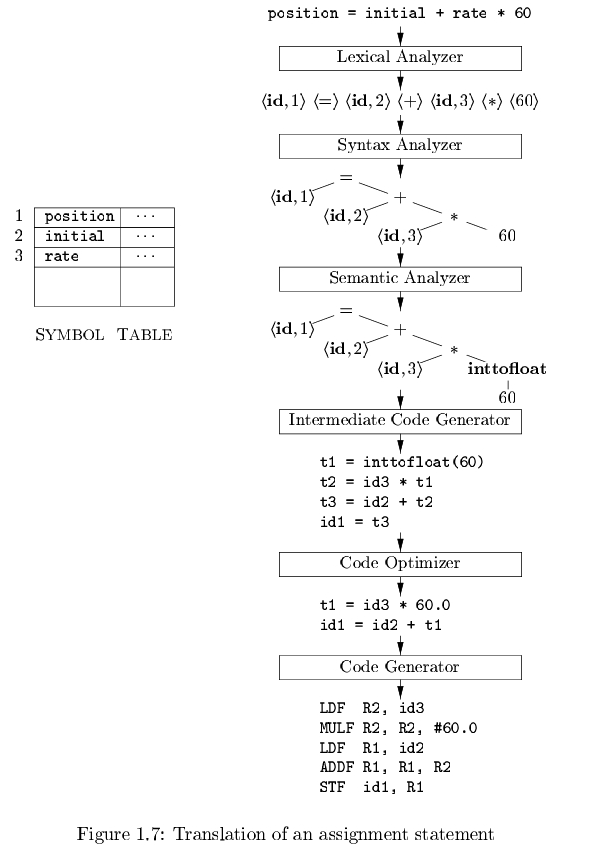
由于可得, Complier会对源程序进行词法分析, 语法分析, 语义分析等, 得到Symbol Table, syntax tree等结构化的信息, 然后生成运行在虚拟机上的intermediate Code, 最终生成目标机器代码.
各环节完成的工作大致如下:
Lexical Anlysis
将 the stream of characters 转换为 meaningful sequences - lexemes.
lexemes具有如下结构
<token-name, attribute-value>
这一步将字节流转换为 lexemes的序列.
Syntax Analysis
这一步将lexemes的序列转换为lexemes的树, 从而包含了优先级.
Semantic Analysis
这一步进行了语义上的分析, 丰富了lexemes的意义.
这一步会完成一个很重要的工作: 类型检查(type checking). 编译器会确认变量的类型, 将其存储到Symbol Table中, 进行类型合法性的检查, 并完成隐式的类型转换(如将int 转换为 float)
Intermediate Code Generation
根据已有的结构化信息, 如Symbol Table和lexemes, 生成抽象的中间代码, 如生成three-address code. 这些代码与指令序列很类似, 但是是指令集无关的.
Code Optimization
对代码进行优化. 代码优化是一门很大的学问, 有着各种各样的trick, ch8会详细展开.
Code Generation
将中间代码转为某个具体指令集上的代码.
Symbol-Table Management
符号表存储了每个name的各种attributes.
如, 对于一般的变量, 存储了
- its name
- its type
- its scope
对于procedure names, 存储了 - its name
- the number and type of its arguments
- the method of passing each argument
- the type returned
符号表应当能够高效地存储和访问各项信息, 具体在ch2讨论.
The Grouping of Phases into Passes
对于各种Phases, 可以将它们作为一个整体看待, 这个整体会完成某些特定的功能, 从而进一步提高抽象层次.
Compiler-Construction Tools
各种"生成编译器的工具". 如果不是用于教学, 或者用于发展自己创建的某门语言的话, 应该没有什么机会用到这些工具.
The Evolution of Programming Languages
CS编年史的部分.
曾经, 我们的计算机体积庞大, 要占据一整栋楼, 所能行使的功能也只有纯粹的计算. 程序员需要手搓机器码, 并将其变成各种开关的闭合 / 电线的拔插 / 纸带的打孔. 这样写出的程序, 可读性和可维护性都差的惊人, 程序的编写和运行也是一种惭愧的折磨. 向前辈们致敬! (双手合十)
The Move to Higer-level Languages
随着时代的演进, 各种各样的高级语言出现了.
从时间或代际上划分, 可分为:
- 第一代: 机器语言
- 第二代: 汇编语言
- 第三代: Fortran, Cobol, Lisp, C, C++, C#, Java等高级通用语言
- 第四代: NOMAD, SQL, Postscript等专门化的语言
- 第五代: Prolog, OPS5等基于逻辑和约束规划的语言
从编程范式上划分, 可分为:
- imperative / how to do: 命令式, 如C, C++, C#, 考虑各种变量与状态, 并通过运算改变它们, 来得到需要的结果.
- declarative / what to do: 陈述式, 如ML, Haskell等Functional languages, 以及ML, Prolog等constraint logic languages, 考虑各种函数过程
von Neumann language: 计算模型是基于von Neumann computer的语言. 大部分语言都属于此类.
object-oriented language: 面向对象的语言. 通过描述各种object以及它们的互动来完成计算任务.
Impacts on Compilers
讲述了编程语言发展对compiler产生的影响.
The Science of Building a Complier
宏观上的一些指导思想.
编译器设计的过程是"抽象并解决某个现实问题"的经典实例:
- take a problem,
- formulate a mathematical abstraction that captures the key characteristics,
- and solve it using mathematical techniques
这个思想有些类似数学建模, 都是理论工具与实际问题相遇时发生的碰撞.
Modeling in Compiler Design and Implementation
Compiler Design的抽象与建模过程运用了许多数学理论, 如Finite-state machines, regular expressions, context-free grammars, trees等等. 这些理论能够帮助我们描述与处理各种对象.
The Science of Code Optimization
对程序进行优化需要有一套完备的理论作为支撑, 如graphs, matrices, and linear programs
同时, 仅仅有理论是不够的, 因为我们在优化过程中遇到的许多问题都不可判定. 因此, 权衡和妥协是必须的.
Applications of Compiler Technology
编译器技术不止用于编译器
Implementations of High-Level Programming Languages
Optimizations for Computer Architectures
- Parallelism
- Memory Hierarchies
- Database Query Interpreters
Design of New Computer Architectures
- RISC (Compared with CISC)
- Specialized Architectures
- Compiled Simulation
Program Translations
- Bianry Translation
- Hardware Synthesis
- Database Query Interpreters
- Compiled Simulation
Software Productivity Tools
- Type Checking
- Bounds Checking
- Memory-ManagementTools
Programming Language Basics
在编译器技术的介绍中, 会涉及到的与Programming Language有关的一些特性
The Static/Dynamic Distinction
此处的"静态/动态"是相对于整个语言而言.
- Most languages, such as C and Java, use static scope
针对"编译器是否能在程序运行前找到变量所处的地址"而言. 例如对于全局变量和静态变量, 在运行前地址就已经确定; 而对于临时变量与局部变量, 它们的位置则处于栈或堆中, 需要在程序运行的过程中动态确认.
Environments and States
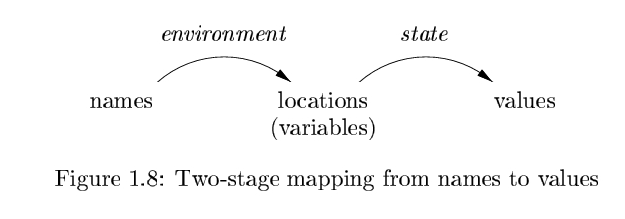
对于某个name, 需要先根据环境(如当前作用域等)确定其地址, 再根据地址中的状态, 获取其具体的值.
Env: 代表了从name到locations的映射.
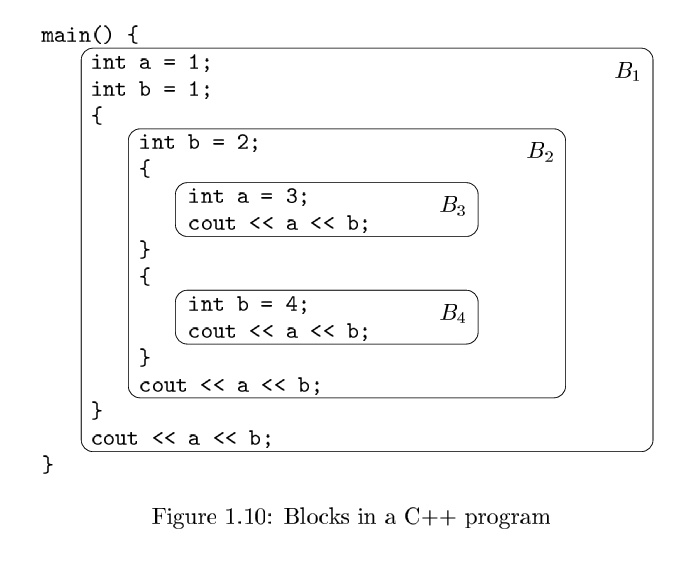
Static Scope and Block Structure
显式地事先声明了变量的作用域(Scope)和代码的作用区间(Block Structure), 分别通过public, private, and protected等关键字以及{ and }等符号.
Explicit Access Control
如C中的public, private, and protected, 用于限定对象属性的访问权限进行规定.
Dynamic Scope
对于name到variable的映射, 取决于最近的procedure中的declaration.
如, 对于C中的宏定义代码
1 |
此时变量a就拥有动态的Scope. 它的具体值取决于x的最近的declaration, 而无法静态的在编译时给出. 是个非常有趣的特性.
Parameter Passing Mechanisms
- Call-by-Value 值传递
- Call-by-Reference 地址传递
- Call-by-name 早期语言的一个机制.
Aliasing
如, 对于形如q(x, y)的函数, 进行如q(a, a)的调用. 那么, 此时的函数内部的x,y变量互为alises.
Summary of Chapter 1
内容很多很杂, 有许多背景性的知识与总体性的概况.
大致了解即可, 尤其是1.4和1.5的部分, 很多都是一些总结性的语言. 这些语言对于我们学习编译器的具体原理没有什么帮助, 但是作为对一门学科的整体性描述而言是必须的. 所以随便看看即可.
各方面细节会在后面详细介绍.
大致编写用时: 2h
