学习编译原理PPT的记录. 相关笔记会另开博客记录. 也可能不会开.
Ch3 词法分析
作用:
词法分析的作用, 规约, 识别
有穷自动机, 词法分析器 生成工具及设计 .
词法分析器: text -> token / Lexeme
语法分析器: get token -> 语义分析
正则表达式
用RE来描述词法单元描述的模型
一些正则表达式的相关定义.
正则表达式用来描述每个token的模式, 如变量的模式为
[a-z, A-Z][a-z, A-Z, 0-9]*;,
状态转换图
和DFA差不多.
某些状态作为终止态, 表示已经找到词素; 某些状态表示最后读入的字符不在词素内, 此时需要回退指针.
引入NFA
NFA与DFA的相互转换
DFA状态最小化: 将相同的状态(不可区分的状态) 合并为可区分状态.
可区分的状态: 如果s, t前进同一个路径, 只有一个是接收态, 那么这个路径将两个串区分
算法: 从 出发, 不断细分, 最终得到最小的DFA.
RE 转换至 NFA.
Ch4 语法分析
输入: token, 输出: 语法树表示.
类型:
- 通用型 (CKY)
- 自顶向下: 处理LL文法
- 自底向上: 处理LR文法

CFG Context Free Grammar, CFG.
-
终结符号.
-
非终结符号
-
推导: 最左推导, 最右推导. (非终结符可能有多个, 选择哪个非终结符的问题)
-
非终结符的推导步骤也有多个, 选择哪个呢?
-
文法进行消除二义性.
-
消除左递归
-
提取左公因子
消除左递归
从立即左递归的形式.
1 | A -> A a / b |
到消除立即左递归的形式
1 | A -> b A' |
间接左递归: 先对非终止符进行排序, 之后进行带入; 若出现左递归则进行求导
提取左公因子: 将公共左公因子提取出来.
自顶向下的分析技术
对于这种技术, 需要进行回溯操作.
预测分析技术
通过在输入中向前看固定多个符号来选择正确的产生式.
考虑两个函数 FIRST(a), FOLLOW(a)
- FIRST 表示 文法符号可能的第一个字符. 其中F X 的符号根据 规则遍历得到; F a 通过遍历X的F得到. 当X包含 空时, 就继续考察其后面的 FX. 有点像串联和并联的思路.


- FOLLOW: 有可能紧跟着非终结符A 的终结符. 当A为最右符号时, 包含结束标记.

LL(1)文法: 从左到右, 最左推导
需要满足一定的性质, 才能使得产生式的选择不再是问题.
预测分析技术: 无左递归 + LL1 文法. 构建预测分析表 (二义性文法的预测分析表: 可能有多重条目, 类似NFA)
非递归的预测分析计划. 采用栈来实现.
表驱动的预测分析技术
自底向上句法分析
Bottom-up Parsing
移进 - 规约技术
LR语法分析技术
简单LR技术 / LR技术 .
实际上是自顶向下的逆过程. 句柄剪枝
移进规约语法分析框架:
移入: Shift
规约: Reduce
接受 / 报错
句柄总是不会出现在中间.
冲突问题: 移入 / 规约冲突, 规约 / 规约冲突
LR语法分析技术: LR 文法.
LR(k)分析: 流行, 无回溯, 高效.
LR(0)项集规范族.
- 增广文法
- 项集闭包 ECLOSE(I)中的元素至少会出现一次, I才有可能出现
- GOTO函数 对于项集I和文法符号 X, GOTO(I, X) 把I转换成 已经出现X符号的情况下, 出现I所需要满足的转换方式 (给定X, 要到达X可能要走的路)
通过一个增广文法, 一个初始项集和一个GOTO, 不断做GOTO操作, 直到没有项集可以加入.
- “闭包 -> GOTO” -> 项集规范族.
SLR items sets



感性上掌握比较容易, 严谨推导证明需要花功夫.
- 通过获得的LR转移自动机是否确定性, 可以确定某个语言是否是LR语言.
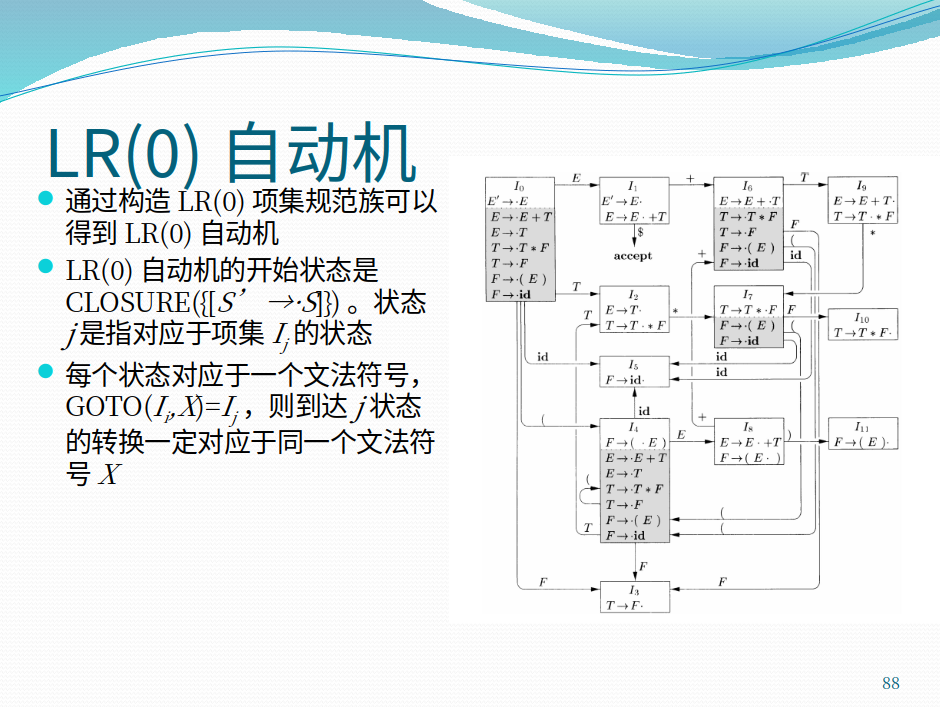
通过上面的转移方程可以得到一个LR(0)表和相关的LR(0)方法.
引入一个栈, 用于存储规约的状态, 可以得到SLR算法 (和LR算法区别不是很大. )

