实现DQN算法前, 打算先做一个baseline, 下面是具体的实现过程.
DQN, double DQN, Duel DQN, Rainbow, DDPG, TD3, SAC, TRPO, PPO
通过stable-baselines3库和 gym库, 以很少的代码行数就实现了baseline算法的运行, 为之后自己手动实现这些算法提供了一个基线.
在下面的代码中, 我们了实现DQN, DDPG, TD3, SAC, PPO. 所需要的库有
1 | PyTorch |
pytorch是一个AI常用的库. 它不是能够直接pip的库, 没有装的朋友可以自行google教程, 或者参考文章后面一点的部分, GPT给出的回答.
除此之外, 我们还需要安装如下的库
1 | pip install gymnasium[all] stable-baselines3 pandas matplotlib |
[!attention]
这些依赖列表可能并不完整
- 在下面的代码中, 我们在离散动作环境
LunarLander-v2上运行了 DQN算法, 在连续动作环境Pendulum-v1上运行了DDPG, TD3, SAC, PPO算法. (关于这些环境的具体含义, 可自行查看gym的官方手册. https://gymnasium.farama.org/index.html ) - 同时, 我们启用了monitor的log并将其存储在
log_dir = "./logs/"中, 用于后面plot函数中, 以图片的形式展现训练成果(plot函数中, 我们直接读取monitor.csv, 并做了一个平滑操作. 具体可查看后面GPT对于monitor.csv文件含义的解释) - 我们也是启用了tensorboard_log并将其存储在
"./agent_cartpole_tensorboard/", 用于在命令行中调用tensorboard --logdir ./agent_cartpole_tensorboard/并在网页端显示模型的训练效果(具体可查看GPT关于tensorboard的解释)
其中, 我们尚未包含TRPO的实现, 因为它不包含在stable-baselines3中, 而仅含在前身 stable-baselines中. 这个旧版本的库需要调用TensorFlow 1.x的接口, 但是TensorFlow 1.x 已经停止更新和维护, 在pip上也没法直接下了. 所以真要折腾起来很麻烦, 建议直接跳过.
同样, 由于stable-baselines3未直接包含Rainbow和 double DQN, Duel DQN的实现, 我们这里同样也不给出. 这些算法之后可能会通过Dopamine来完成.
[!attention]
对比GPT给出的代码, 完整代码中更改了部分内容, 包括但不限于模型最终存储的位置, tensorboard_log存储的位置,import gymnasium as gym, 以及清空tensorboard_log的操作等等
这些改动有的是因为GPT给出了错误的实现 (例如直接import gym是不对的); 有的是因为代码的意图改变了(例如完整代码中运行的模型不止DQN, 所以应该把dqn_cartpole_tensorboard改掉. ).
请大家注意这些改动, 直接复制粘贴GPT给出的代码会出现一些问题.
以下是完整代码:
1 | import gymnasium as gym |
[!attention]
下面是GPT关于整个过程的回答和说明, 很多地方有错误, 请自行甄别!
例如, 代码部分有漏洞(例如gym库已经改称为gymnasium), 直接复制是跑不了的; 同时提供的解决方案也有问题, 例如, 无法直接通过更改参数的方式在stable-baselines3中实现Double DQN: DQN里面根本没有double_q这个参数.
希望尝试的朋友, 请复制上面的完整代码, 然后配合着下面GPT的说明使用; GPT的回答仅供大家进一步理解相关的细节. 请自行甄别答案是否有问题, 不要完全相信!!!
关于安装 PyTorch
要在 Python 中安装 PyTorch,可以通过 pip 安装适合你的系统和 CUDA 版本的 PyTorch。以下是安装步骤:
1. 检查是否需要 CUDA 支持
-
CPU-only:如果你不需要 GPU 加速,可以安装仅支持 CPU 的版本。
-
CUDA 版本:如果你的计算机有 NVIDIA GPU,并且安装了 CUDA,你需要知道 CUDA 的版本(例如 CUDA 11.7、11.8)。可以使用以下命令来确认 CUDA 版本:
1
nvcc --version
2. 访问 PyTorch 官方安装页面
PyTorch 提供了一个便捷的安装指引页面,可以根据你的系统和需求生成安装命令:PyTorch 安装指引
3. 使用 pip 安装 PyTorch
根据你的 CUDA 版本选择相应的安装命令。
-
仅使用 CPU:
1
pip install torch torchvision torchaudio
-
使用 CUDA 11.8:
1
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
-
使用 CUDA 11.7:
1
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
-
使用 CUDA 10.2:
1
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu102
4. 验证安装
安装完成后,可以在 Python 中导入 torch 来验证安装是否成功:
1 | import torch |
如果 torch.cuda.is_available() 返回 True,说明 PyTorch 能够检测到 CUDA 支持。
代码实现大致流程
在使用 stable-baselines3 时,可以通过保存训练过程中的日志,并使用 Matplotlib 绘制训练曲线。下面是具体步骤:
1. 安装 stable-baselines3 及辅助库
如果没有安装 stable-baselines3 和 tensorboard,可以通过以下命令安装:
1 | pip install stable-baselines3 tensorboard matplotlib |
2. 配置训练日志
在训练模型时,使用 Monitor 和 tensorboard_log 选项记录训练过程。
1 | import gym |
3. 使用 TensorBoard 查看训练曲线
训练后,你可以使用 tensorboard 命令查看训练曲线:
1 | tensorboard --logdir ./dqn_cartpole_tensorboard/ |
在浏览器中打开链接(通常是 http://localhost:6006 ),可以查看累积奖励(episode reward)、损失等指标的变化。
4. 使用 Matplotlib 绘制训练曲线
可以从 Monitor 日志中读取数据,并使用 Matplotlib 绘制奖励曲线:
1 | import pandas as pd |
解释
tensorboard_log:设置 TensorBoard 日志目录,可以通过 TensorBoard 实时查看训练曲线。Monitor:会记录每个 episode 的奖励和其他信息,保存为 CSV 文件。
关于gym环境
有一些更具挑战性的 Gym 环境可以尝试,例如:
-
MountainCar-v0:一个经典的控制任务,目标是驱动小车越过山顶。这一环境比
CartPole-v1难度更大,因为必须在能量有限的情况下学会摆动小车,逐渐积累足够的动能。1
env = gym.make("MountainCar-v0")
-
LunarLander-v2:控制一个月球着陆器在给定区域安全着陆,需要精确调整推力和方向。这个任务包含更多的状态信息和更复杂的控制目标,非常适合强化学习算法。
1
env = gym.make("LunarLander-v2")
-
Acrobot-v1:双摆控制任务,需要将一个链条状的双关节摆臂摆动至目标高度。因为有两个摆臂关节,动作的控制难度增加,DQN 在这个任务上会面临更大的挑战。
1
env = gym.make("Acrobot-v1")
-
Atari 游戏环境:这些环境(如
Breakout-v0,Pong-v0等)包含大量像素输入,是强化学习研究中的经典难题。Atari 游戏的训练数据较为复杂,因此需要更大的网络和更长的训练时间。1
2from stable_baselines3.common.atari_wrappers import AtariWrapper
env = AtariWrapper(gym.make("BreakoutNoFrameskip-v4")) -
MuJoCo 物理仿真环境(例如
Ant-v2,HalfCheetah-v2,Humanoid-v2):这些环境模拟复杂的机器人运动,状态空间维度较高且连续动作控制较难。注意,这些环境需要安装 MuJoCo 支持,并适合使用策略梯度类算法(如 PPO、SAC 等)。1
env = gym.make("Ant-v2")
对于更复杂的任务(如 LunarLander-v2 或 MuJoCo 环境),DQN 可能需要更多的训练时间和更大的网络结构,以适应更高维度的状态空间和复杂的动作控制需求。
在强化学习中,动作空间的类型会影响算法的适用性。不同算法对离散动作空间和连续动作空间的支持如下:
1. DQN(Deep Q-Network)
- 支持的动作空间:离散
- 解释:DQN 是基于 Q-learning 的算法,使用深度神经网络来估计 Q 值。它只能处理离散的动作空间,因为 Q-learning 方法无法直接应用于连续动作空间。
- 示例环境:CartPole、MountainCar 等。
2. DDPG(Deep Deterministic Policy Gradient)
- 支持的动作空间:连续
- 解释:DDPG 是一种基于 Actor-Critic 的算法,专门设计用于解决连续动作空间问题。它通过策略网络输出连续动作,并通过 Q 网络来评估动作的价值。
- 示例环境:Pendulum、MuJoCo 环境等。
3. TD3(Twin Delayed DDPG)
- 支持的动作空间:连续
- 解释:TD3 是对 DDPG 的改进,通过双 Q 网络、延迟更新等方法减小了 DDPG 的高估偏差。它同样适用于连续动作空间。
- 示例环境:BipedalWalker、MuJoCo 环境等。
4. SAC(Soft Actor-Critic)
- 支持的动作空间:连续
- 解释:SAC 是一种基于最大熵的策略梯度算法,适用于连续动作空间。它通过在策略中加入熵项,提升了策略的探索性和稳定性。
- 示例环境:Humanoid、Ant、HalfCheetah 等连续动作环境。
5. PPO(Proximal Policy Optimization)
- 支持的动作空间:离散和连续
- 解释:PPO 是一种基于策略梯度的算法,适用于离散和连续动作空间。它通过引入限制更新范围的优化目标,提高了策略更新的稳定性。
- 示例环境:Atari 环境(离散)、BipedalWalker(连续)等。
总结
| 算法 | 支持的动作空间 |
|---|---|
| DQN | 离散 |
| DDPG | 连续 |
| TD3 | 连续 |
| SAC | 连续 |
| PPO | 离散和连续 |
在选择算法时,确保算法的动作空间支持与你的环境动作空间相匹配。
关于monitor
在 stable-baselines3 中,Monitor 默认不会直接保存日志为 CSV 文件。要保存为 CSV 文件,可以手动指定保存路径。以下是修改后的代码:
1 | import gym |
读取 CSV 文件并绘制训练曲线
1 | import pandas as pd |
说明
Monitor(env, log_dir + "monitor.csv"):指定保存的日志文件路径,这样训练数据会保存到 CSV 文件中。skiprows=1:Monitor 文件的第一行是注释,读取时需跳过。
stable-baselines3 的 Monitor 中保存的日志文件包含了训练过程中收集的每个 episode 的相关信息,主要用于分析和可视化训练效果。这些数据一般会以 CSV 格式保存,每行记录一个 episode 的信息。文件中的字段通常包括:
-
r (reward):每个 episode 累积的总奖励。这是强化学习中的关键指标之一,表示智能体在该 episode 中所获得的奖励之和。
-
l (length):每个 episode 中的步数,即从 episode 开始到 episode 结束时经历的时间步总数。这个指标反映了智能体在环境中存活的时间,通常越长越好(具体取决于任务目标)。
-
t (time):表示从训练开始到该 episode 结束时的总运行时间(秒)。此字段帮助了解训练的总耗时,可以用于评估模型在不同训练阶段的学习速度。
示例日志文件
Monitor 生成的 CSV 文件(monitor.csv)的内容可能如下所示:
1 | # {"t_start": 1625509883.23456, "env_id": "CartPole-v1"} |
- 第一行:注释行,包含
t_start(训练开始时间)和env_id(环境 ID)。 - r 列:每个 episode 的总奖励。
- l 列:每个 episode 的步数。
- t 列:每个 episode 结束时的累计运行时间。
如何调整算法的神经网络大小
在 stable-baselines3 中,可以通过自定义 DQN 的网络结构来调整神经网络的大小。默认情况下,stable-baselines3 使用两层隐藏层的全连接网络,每层包含 64 个神经元。你可以通过修改 policy_kwargs 参数来设置自定义的网络大小。
1. 自定义网络大小
使用 policy_kwargs 来定义网络的隐藏层大小,例如使用更大的网络或增加隐藏层的数量。以下示例展示了如何定义一个包含三层隐藏层(每层 128 个神经元)的网络结构:
1 | from stable_baselines3 import DQN |
2. 更复杂的网络结构
可以使用更复杂的架构,例如不同层数的隐藏层:
- 如果需要不同大小的层,可以在
net_arch中指定,例如[256, 128, 64]。 net_arch接受列表形式的层配置,列表中的每个数字表示每层的神经元数量。
1 | # 定义不同大小的隐藏层网络结构 |
3. 自定义激活函数等高级配置
如果想进一步自定义,可以指定激活函数、正则化等。policy_kwargs 提供了更细致的设置选项,但 stable-baselines3 的 DQN 模型主要支持通过 net_arch 配置层结构。
通过这种方式,你可以很方便地调整 DQN 的网络规模,以适应不同难度的环境或更高维度的状态空间。
各种算法的实现
可以使用 stable-baselines3 和 rl-algorithms 等库来实现这些算法。以下是这些算法的概述和如何实现它们的步骤。
1. 使用 stable-baselines3 实现基础算法
stable-baselines3 支持多种强化学习算法,包括 DQN、DDPG、TD3、SAC、TRPO 和 PPO。以下是各算法的实现示例:
1 | pip install stable-baselines3 |
(1) DQN
1 | from stable_baselines3 import DQN |
(2) DDPG
1 | from stable_baselines3 import DDPG |
(3) TD3
1 | from stable_baselines3 import TD3 |
(4) SAC
1 | from stable_baselines3 import SAC |
(5) TRPO
1 | from stable_baselines3 import TRPO |
(6) PPO
1 | from stable_baselines3 import PPO |
2. 扩展 DQN 实现(Double DQN、Duel DQN、Rainbow)
[!warning]
这些是不对的.stable-baselines3并不能直接实现Double DQN. 同时rl-algorithms也不是一个好的rainbow实现方法. 原因在前面以及提到了
stable-baselines3 中的 DQN 主要支持基础 DQN 和 Double DQN 的实现。可以通过以下方法扩展它们:
- Double DQN: 设置
double_q=True即可启用 Double DQN。 - Dueling DQN: 需要使用自定义网络,设置
dueling=True,并配置policy_kwargs。 - Rainbow: 由于
stable-baselines3暂不直接支持 Rainbow,可以使用rl-algorithms或其他库,如dopamine。
3. 使用 rl-algorithms 实现 Rainbow
如果希望实现更复杂的 DQN 变体(如 Rainbow),可以考虑 rl-algorithms 或 dopamine 库,这些库包含对 Rainbow 的支持。
4. 启用 TensorBoard 监控
对于所有算法,你都可以使用 tensorboard_log 参数来记录训练过程,并在 TensorBoard 中可视化训练效果:
1 | model = DQN("MlpPolicy", env, verbose=1, tensorboard_log="./logs/") |
5. 自定义超参数和网络结构
可以根据需要自定义网络结构或超参数,例如设置 policy_kwargs 自定义网络大小,或修改学习率、探索率等参数。
通过这些步骤,基本可以实现和配置各类强化学习算法的训练,并支持自定义和监控训练过程。
关于Rainbow
Rainbow 是一个较为复杂的算法, 所以它的调用也复杂一些
GPT推荐了 rl-algorithms和 Dopamine 两种实现. 其中rl-algorithms已经被证明是不太可行的.
rl-algorithms 库包含了强化学习算法的实现,包括 DQN 的不同变体,例如 Rainbow。下面是如何使用 rl-algorithms 实现 Rainbow 的步骤。
1. 安装 rl-algorithms
首先确保安装 rl-algorithms,可以直接从 GitHub 下载:
1 | git clone https://github.com/medipixel/rl_algorithms.git |
2. 使用 rl-algorithms 运行 Rainbow DQN
在 rl-algorithms 中,可以通过命令行指定算法配置来运行 Rainbow DQN。rl-algorithms 中包含了预配置的训练脚本,可以直接使用命令来训练 Rainbow DQN。
使用命令行运行 Rainbow DQN
以下是一个使用 Rainbow DQN 在 Atari 环境中训练的示例:
1 | python run_atari.py --cfg-path ./configs/atari/rainbow.yaml |
3. 配置 Rainbow 训练参数
rl-algorithms 的配置文件采用 YAML 格式,位于 configs/atari/rainbow.yaml。可以根据需求调整文件中的超参数,比如 num_atoms、v_min 和 v_max 等。
配置文件 rainbow.yaml 示例:
1 | agent: |
4. 启用 TensorBoard 日志
在训练过程中,rl-algorithms 会自动记录 TensorBoard 日志。日志默认保存在 results 文件夹中,可以使用以下命令来启动 TensorBoard:
1 | tensorboard --logdir=./results |
5. 自定义训练代码
如果你希望直接在代码中实现 Rainbow,可以参考以下代码:
1 | from rl_algorithms import RainbowAgent |
通过这些步骤,即可在 rl-algorithms 中实现和运行 Rainbow 算法。
要实现 Rainbow DQN 和其他复杂的强化学习算法,可以使用 rl-algorithms 库或 Dopamine 框架,Dopamine 提供了 Rainbow 的完整实现。以下是基于 Dopamine 来实现 Rainbow 的示例。
1. 安装 Dopamine
Dopamine 是由 Google 开发的强化学习研究平台,内置了 DQN 及其变体(如 Rainbow)。首先,需要安装 Dopamine:
1 | pip install dopamine-rl |
2. 配置 Rainbow 训练
Dopamine 提供了直接使用 Rainbow 的方法,可以通过修改配置文件指定 Rainbow 相关参数。
示例代码
以下示例展示了如何在 Atari 游戏环境中使用 Dopamine 运行 Rainbow:
1 | from dopamine.jax import rainbow_agent |
3. 修改配置文件
Dopamine 的 rainbow.gin 配置文件位于 dopamine/configs/rainbow.gin,可在文件中自定义参数,例如:
1 | JaxRainbowAgent.network = @RainbowNetwork |
4. 启用 TensorBoard 可视化
Dopamine 也支持生成 TensorBoard 日志,日志文件会保存在 save_path 指定的目录中。可以运行以下命令启动 TensorBoard:
1 | tensorboard --logdir=./rainbow_checkpoints |
然后在浏览器中打开 http://localhost:6006,查看训练曲线。
Dopamine 的 Rainbow 特性
Dopamine 实现的 Rainbow 包括以下增强特性:
- Double DQN:防止过高估计值函数。
- Dueling Network:使用分离的价值和优势函数。
- Prioritized Experience Replay:优先级回放提升效率。
- Multi-step Learning:提高学习稳定性。
- Categorical DQN:对 Q 值分布进行建模。
这种配置使得 Rainbow 适合在复杂环境(如 Atari 游戏)上表现优越。
最终结果
运行 1e-6个时间步得到的结果. 跑下来还是需要个几十分钟的.
可以发现, 各种算法在倒立摆环境上都表现的很好
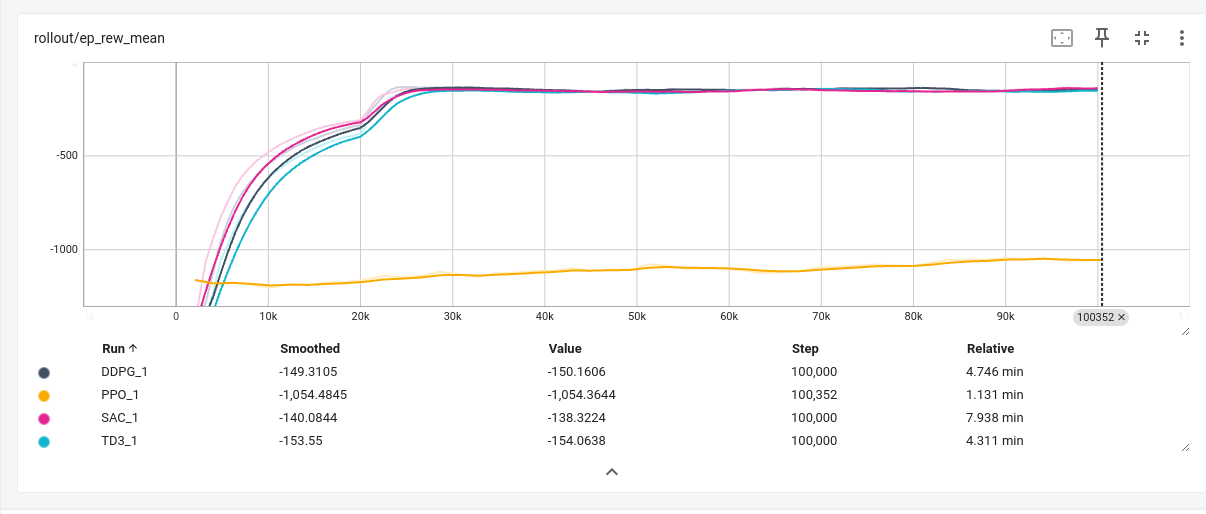
总结
- 用最少的代码量, 实现了DQN等基线算法, 为后面自己手写这些算法提供了一个参照.
stable_baselines3很好用, 但是很多算法也不能直接用它来实现.- 关于Double DQN 和 Dueling DQN以及RainBow, 后面应该会寻找别的实现方法.
- “GPT也可能会犯错”. 常见的错误类型是把过时的信息当真了. 应当仔细甄别GPT的回答.
